Introduction to fragile
Contents
Introduction to fragile#
Note
The notebook version of this example is available in the examples section as 01_getting_started.ipynb
This is a tutorial that explains how to crate a Swarm to sample
Atari games from the OpenAI gym library. It covers how to
instantiate a Swarm and the most important parameters needed to
control the sampling process.
Structure of a Swarm#
The Swarm is the class that implements the algorithm’s evolution loop, and controls all the other classes involved in solving a given problem:
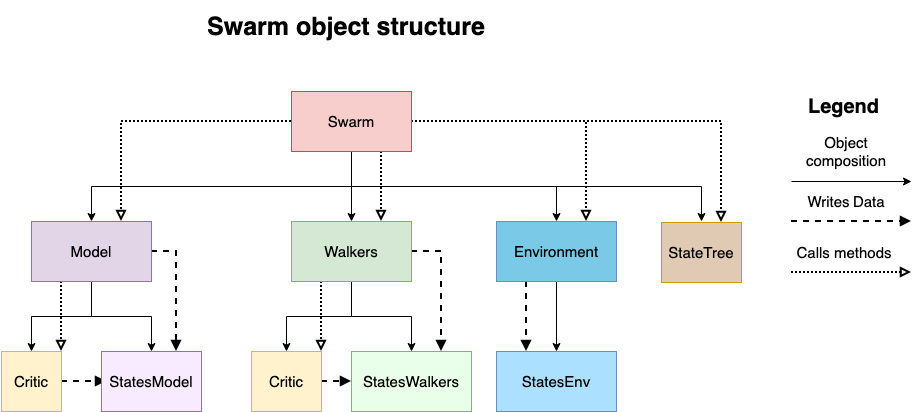
swarm architecture#
For every problem we want to solve, we will need to define callables that return instances of the following classes:
Environment: Represents problem we want to solve. Given states and actions, it returns the next state.
Model: It provides an strategy for sampling actions (Policy).
Walkers: This class handles the computations of the evolution process of the algorithm.
StateTree: It stores the history of states samples by the Swarm.
Critic: This class implements additional computation, such as a new reward, or extra values for our policy.
Choosing to pass callables to the Swarm instead of instances is a design decision that simplifies the deployment at scale in a cluster, because it avoids writing tricky serialization code for all the classes.
Defining the Environment#
For playing Atari games we will use the interface provided by the
plangym package. It is a
wrapper of OpenAI gym that allows to easily set and recover the state
of the environments, as well as stepping the environment with batches of
states.
The following code will initialize a plangym.Environment for an
OpenAI gym Atari game. The game names use the same convention as the
OpenAI gym library.
In order to use a plangym.Environment in a Swarm we will need to
define the appropriate Callable object to pass as a parameter.
fragile incorporates a wrapper to use a plangym.AtariEnvironment
that will take care of matching the fragile API and constructing the
appropriate StatesEnv class to store its data.
The environment callable does not take any parameters, and must return an instance of fragile.BaseEnvironment.
from plangym import AtariEnvironment
from fragile.core import DiscreteEnv
def atari_environment():
game_name = "MsPacman-ram-v0"
plangym_env = AtariEnvironment(
name=game_name,
clone_seeds=True,
autoreset=True,
)
return DiscreteEnv(env=plangym_env)
Using the ParallelEnv located in the distributed module. It is a wrapper that allows any Environment to be run in parallel using the multiprocessing module. It takes a Callable object that returns an Environment and it spawns the target number of processed to run the make_transitions function of the Environment in parallel.
from fragile.distributed import ParallelEnv
env_callable = lambda: ParallelEnv(atari_environment, n_workers=4)
Defining the Model#
The Model defines the policy that will be used to sample the Environment. In this tutorial we will be using a random sampling strategy over a discrete uniform distribution. This means that every time we sample an action, the Model will return an integer in the range [0, N_actions] for each state.
By default each action will be applied for one time step. In case you want to apply the actions a different number of time steps it is possible to use a Critic. The Critics that allow you to sample time steps values for the actions can be found in fragile.core.dt_samplers.
In this example we will apply each sampled action a variable number of time steps using the GaussianDt. The GaussianDt draws the number of time steps for each action from a normal distribution.
The model callable passed to the Swarm takes as a parameter the Environment and returns an instance of Model.
from fragile.core import GaussianDt, GaussianDt
dt = GaussianDt(min_dt=3, max_dt=1000, loc_dt=4, scale_dt=2)
model_callable = lambda env: DiscreteUniform(env=env, critic=dt)
Storing the sampled data inside a HistoryTree#
It is possible to keep track of the sampled data by using a HistoryTree. This data structure will construct a directed acyclic graph that will contain the sampled states and their transitions.
Passing the prune_tree parameter to the HistoryTree we can choose to
store only the branches of the HistoryTree that are being explored.
If prune_tree is True all the branches of the graph with no
walkers will be removed after every iteration, and if it is False
all the visited states will be kept in memory.
In order to save memory we will be setting it to True.
With the names attribute, we can control the data that is stored in the search tree.
In this example we will be saving the state of the atari emulator, the actions and the number of times the actions have been applied at every environment step.
from fragile.core.tree import HistoryTree
tree_callable = lambda: HistoryTree(names=["states", "actions", "dt"], prune=True)
Initializing a Swarm#
Once we have defined the problem-specific callables for the Model and the Environment, we need to define the parameters used by the algorithm:
n_walkers: This is population size of our algorithm. It defines the number of different states that will be explored simultaneously at every iteration of the algorithm. It will be equal to thebatch_sizeof the States (size of the first dimension of the data they store).max_epochs: Maximum number of iterations that the Swarm will execute. The algorithm will stop either when all the walkers reached a death condition, or when the maximum number of iterations is reached.reward_scale: Relative importance given to the Environment reward with respect to the diversity score of the walkers.distance_scale: Relative importance given to the diversity measure of the walkers with respect to their reward.minimize: IfTrue, the Swarm will try to sample states with the lowest reward possible. IfFalsethe Swarm will undergo a maximization process.
n_walkers = 64 # A bigger number will increase the quality of the trajectories sampled.
max_epochs = 500 # Increase to sample longer games.
reward_scale = 2 # Rewards are more important than diversity.
distance_scale = 1
minimize = False # We want to get the maximum score possible.
from fragile.core import Swarm
swarm = Swarm(
model=model_callable,
env=env_callable,
tree=tree_callable,
n_walkers=n_walkers,
max_epochs=max_epochs,
prune_tree=prune_tree,
reward_scale=reward_scale,
distance_scale=distance_scale,
minimize=minimize,
)
By printing a Swarm we can get an overview of the internal data it
contains.
print(swarm)
Best reward found: -inf , efficiency 0.000, Critic: None
Walkers iteration 0 Dead walkers: 0.00% Cloned: 0.00%
Walkers States:
id_walkers shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
compas_clone shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
processed_rewards shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
virtual_rewards shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
cum_rewards shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
distances shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
clone_probs shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
will_clone shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
alive_mask shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
end_condition shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
best_reward shape None Mean: nan, Std: nan, Max: nan Min: nan
best_obs shape None Mean: nan, Std: nan, Max: nan Min: nan
best_state shape None Mean: nan, Std: nan, Max: nan Min: nan
distance_scale shape None Mean: nan, Std: nan, Max: nan Min: nan
critic_score shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
Env States:
states shape (64, 1021) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
rewards shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
ends shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
game_ends shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
Model States:
actions shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
dt shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
Visualizing the sampling#
We will be using the Atari visuzalizer to see how the sampling process
evolves. For more information about how the visualizer works please
refer to the dataviz module tutorial.
from fragile.dataviz.swarm_viz import AtariViz
import holoviews
holoviews.extension("bokeh")
swarm_viz = AtariViz(swarm, stream_interval=10)
swarm_viz.plot()


Running the Swarm#
In order to execute the algorithm we only need to call run_swarm. It
is possible to display the internal data of the Swarm by using the
print_every parameter. This parameter indicates the number of
iterations that will pass before printing the Swarm.
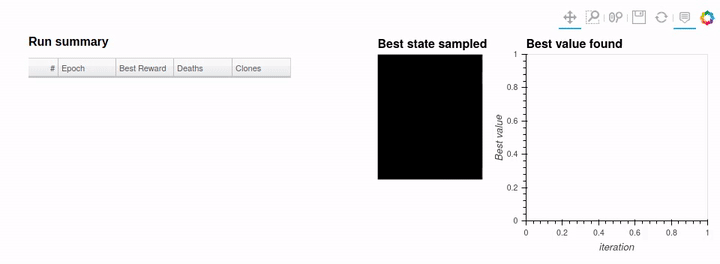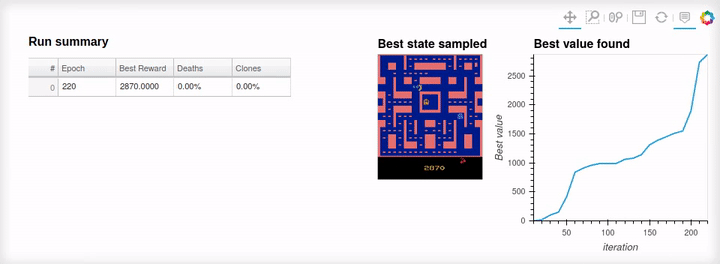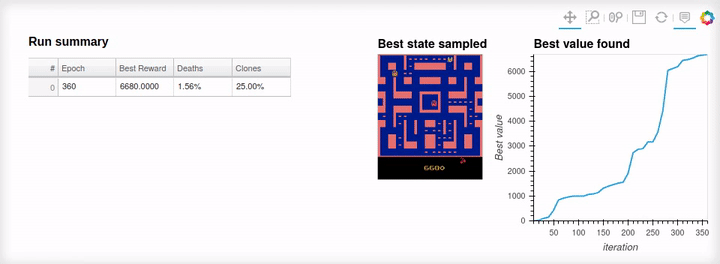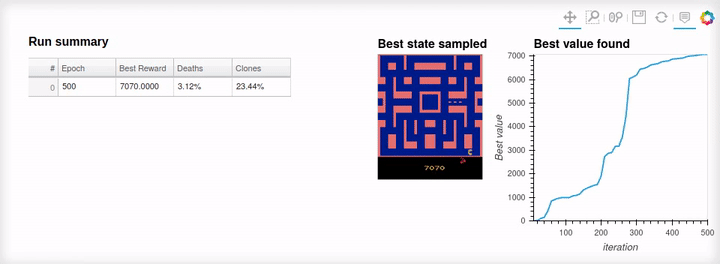
_ = swarm_viz.run(report_interval=50)
Best reward found: 6530.0000 , efficiency 0.808, Critic: None
Walkers iteration 451 Dead walkers: 10.94% Cloned: 31.25%
Walkers States:
id_walkers shape (64,) Mean: 185485787032307136.000, Std: 4859332449700356096.000, Max: 8627791072916286464.000 Min: -9121479801778132992.000
compas_clone shape (64,) Mean: 32.891, Std: 19.501, Max: 63.000 Min: 0.000
processed_rewards shape (64,) Mean: 1.098, Std: 0.156, Max: 1.239 Min: 0.000
virtual_rewards shape (64,) Mean: 1.308, Std: 0.811, Max: 2.855 Min: 0.000
cum_rewards shape (64,) Mean: 6477.812, Std: 202.117, Max: 6530.000 Min: 4880.000
distances shape (64,) Mean: 1.048, Std: 0.590, Max: 1.986 Min: 0.100
clone_probs shape (64,) Mean: 0.654, Std: 2.171, Max: 10.511 Min: -0.934
will_clone shape (64,) Mean: 0.312, Std: 0.464, Max: 1.000 Min: 0.000
alive_mask shape (64,) Mean: 0.891, Std: 0.312, Max: 1.000 Min: 0.000
end_condition shape (64,) Mean: 0.109, Std: 0.312, Max: 1.000 Min: 0.000
best_reward shape None Mean: nan, Std: nan, Max: nan Min: nan
best_obs shape (128,) Mean: 78.711, Std: 82.113, Max: 255.000 Min: 0.000
best_state shape (1021,) Mean: 45.375, Std: 76.181, Max: 255.000 Min: 0.000
distance_scale shape None Mean: nan, Std: nan, Max: nan Min: nan
critic_score shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
Env States:
states shape (64, 1021) Mean: 45.266, Std: 76.287, Max: 255.000 Min: 0.000
rewards shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
ends shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
game_ends shape (64,) Mean: 0.000, Std: 0.000, Max: 0.000 Min: 0.000
Model States:
actions shape (64,) Mean: 3.750, Std: 2.562, Max: 8.000 Min: 0.000
dt shape (64,) Mean: 3.688, Std: 1.059, Max: 7.000 Min: 3.000
Visualizing the sampled game#
We will extract the branch of the StateTree that achieved the
maximum reward and use its states and actions in the
plangym.Environment. This way we can render all the trajectory using
the render method provided by the OpenAI gym API.
The iterate_branch method of the HistoryTree takes the id of an state.
It returns the data stored for the path that starts at the root node of the search
tree and finishes at the state with the provided id.
import time
from fragile.core.utils import get_plangym_env
env = get_plangym_env(swarm) # Get the plangym environment used by the Swarm
for s, a, dt in swarm.tree.iterate_branch(swarm.best_id):
env.step(state=s, action=a, n_repeat_action=dt)
env.render()
time.sleep(0.05)