Architecture
Contents
Architecture#
Class descriptions#
The fragile framework is designed to quickly implement and test new FractalAI based algorithms. The different classes are combined using composition to isolate the different aspects of the algorithms:
Swarm: It defines the main computation loop for the algorithm, and it coordinates all the other classes involved in the algorithm.
The following classes represent different aspects of modelling a given problem. They are state-less, and they write and save data to the States.
Environment: It represents the problem that is being solved, and it allows to sample new states as the algorithm evolves.
Model: This implements the policy used to sample new actions that will be applied to the Environment.
Walkers: This class takes care of the data processing necessary to implement the FractalAI algorithms.
All the data needed to make a Swarm evolve is stored inside States, and all the historical data generated is manged by the StateTree.
The States contain functionality for storing, accessing and cloning all the data of its respective classes.
StateTree: Data structure that stores the data generated by the algorithm, keeping track of its history as a directed acyclic graph.
StateEnv: Contains the data provided by the Environment, and it describes the problem being solved. It contains at least the following attributes:
states: This data tracks the internal state of the
Environmentsimulation, and they are only used to save and restore its state.observs: This is the data that corresponds to the observations of the current
Environmentstate. The observations are used for calculating distances.rewards: This vector contains the rewards associated with each observation.
oobs: Stands for Out Of Bounds. It is a vector of booleans that represents and arbitrary boundary condition. If a value is
Truethe corresponding states will be treated as being outside theEnvironmentdomain. The states considered out of bounds will be avoided by the sampling algorithms.terminals: Vector of booleans representing the successful termination of an environment. A
Truevalue indicates that theEnvironmenthas successfully reached a terminal state that is not out of bounds.
StatesModel: Contains the data provided by the :class:Model. This data describes the internal state of the Model, and the actions applied to the Environment.
actions: Array containing the actions that will be applied to the states.
StatesWalkers: This data describes the internal state of the Walkers.
id_walkers: Array of of integers that uniquely identify a given state. They are obtained by hashing the states.
compas_clone: Array of integers containing the index of the walkers selected as companions for cloning.
processed_rewards: Array of normalized rewards. It contains positive values with an average of 1. Values greater than one correspond to rewards above the average, and values lower than one correspond to rewards below the average.
virtual_rewards: Array containing the virtual rewards assigned to each walker.
cum_rewards: Array of rewards used to compute the virtual rewards. This value can accumulate the rewards provided by the
Environmentduring an algorithm run.distances: Array containing the similarity metric of each walker used to compute the virtual rewards.
clone_probs: Array containing the probability that a walker clones to its companion during the cloning phase.
will_clone: Boolean array. A
Truevalue indicates that the corresponding walker will clone to its companion.in_bounds: Boolean array. A
Truevalue indicates that a walker is in the domain defined by theEnvironment.
The StatesWalkers also track the data associated with the best state found during the algorithm run:
best_state: State of the walker with the best
cum_rewardfound during the algorithm run.best_obs: Observation corresponding to the
best_state.best_reward: Best
cum_rewardfound during the algorithm run.best_id: Integer representing the hash of the
best_state.
Class dependency#
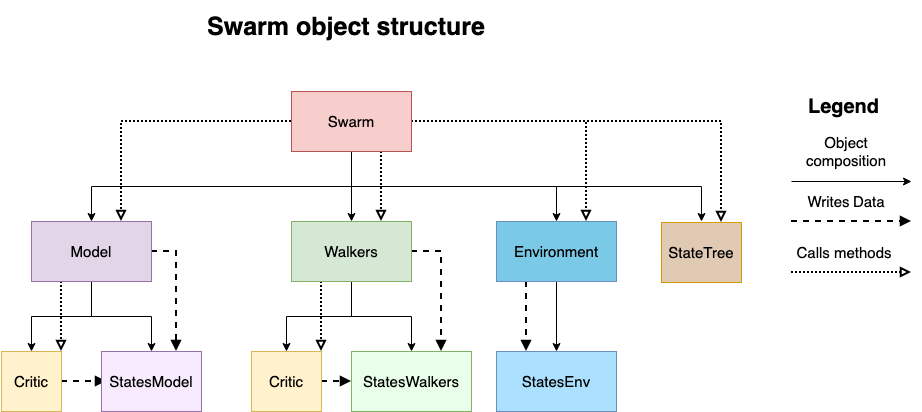
Composition relationship among the different classes#
Swarm algorithm loop#
The algorithm loop executed when run_swarm is called executes the following methods of the classes listed above.
Each method name is colored according to the class that implements it. After the method name are listed inside parenthesis
the different States classes that will be read, and after the -> are described the States that each method modifies.
reset
reset -> StatesEnv (SE)
reset -> StatesModel (SM)
reset -> StatesWalkers (SW)
reset
While not calculate_end_condition then run_step:
step_and_update_best
1.1 update_best (SE) -> SW
1.2 fix_best (SW) -> SW, SE
1.3 step_walkers
1.3.1 predict (SE , SM, SW) -> SM
1.3.2 step (SE , SM, SW) -> SE
1.3.3 update_states (SE , SM) -> SE , SM, SW
1.3.4 update_id (SW) -> SW
1.3.5 add_states (SE , SM, SW)
balance_and_prune
2.1 balance
2.2 calculate_distances (SE) -> SW
2.3 calculate_virtual_reward (SW) -> SW
2.4 update_clone_probs (SW) -> SW
2.5 clone_walkers (SW) -> SW, SE, SM
2.6 prune_tree